

每秒800M IO流量--案例分享(一)
问题描述:
客户反映,数据库服务器的IO量非常大,达到每秒800M,几乎将HBA的带宽打满,交易出现缓慢的情况。分析过程:
收集当前时段的Oracle AWR报告,找到Load Profile部分,如下图所示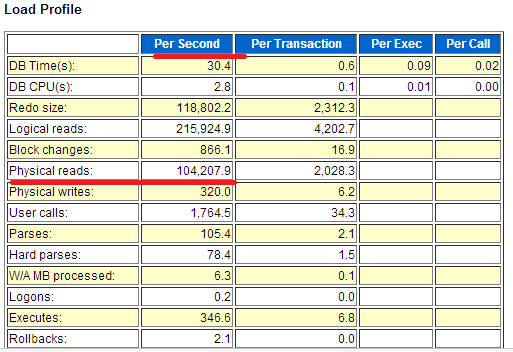
可以看到:
每秒的物理读Physical Reads达到104,207个BLOCK,每个BLOCK的大小是8K
即每秒的IO量达到104207*8K=814M!
IO的流量太大了,几乎打满了HBA所支持的吞吐,影响到整体的性能是必然的!

根据上述知识点,我们知道,ORACLE采用内存换IO的策略,避免出现过多IO。
那么我们不妨猜一下,是否是因为buffer cache太小导致IO无法缓存呢?
进一步检查AWR报告中的”Cache Sizes”部分
如下图所示,buffer cache大小仅为128M!而shared pool大小为15,232M.
而该服务器配置了60G的内存!
我们提到,buffer cache可以设置到服务器内存的40%,即24G。
通过查找AWR报告中的”Buffer Pool Advisory”,如下图所示,可以看到:
当buffer cache从128M设置到256M时,IO即物理读的个数将从3600万下降到1900万,就下降了一倍!
原因
难道是配置失误?不是的。实际上,客户通过一个memory_target参数设置了为ORACLE数据库分配总计40G的内存。这是一种常见的做法,即交给ORACLE来动态分配在SGA和PGA之间,在SGA内部各个组件的内存大小。由于内存动态调整算法的不完善,导致过多的内存分给了PGA而SGA不够,又由于应用程序绑定变量的使用不够理想,导致shared pool不断的膨胀,一步一步地,将buffer cache压缩到了只剩128M.解决方法
为buffer cache设定一个基准值20G后,IO高的问题得到解决。
我们首先接触了第一个IO高的案例,接下来,我们通过一个例子来进一步的学习ORACLE的工作过程,以及更多的了解ORACLE的IO特点。
活得明白--一个例子说明ORACLE的工作过程
当客户端或者应用程序发起一条UPDATE语句时,到底经历了哪些事情和那些IO?
简化后的过程如下:
客户端连接到数据库后,数据库服务器上将创建一个LOCAL=NO的进程来专门为这个客户端服务
客户端发起update T set id=5 where id=3的SQL语句,其中表T的大小为1G,表上不存在任何索引
服务器上的服务进程(LOCAL=NO),将判断表T的数据BLOCK在内存中的buffer cache是否存在,如果不存在,则由服务进程发起IO,从磁盘先后将1G的数据读到内存中。具体来说,是先读取16个BLOCK即128K(一个BLOCK可以存储几十到几百条不等的记录),然后逐个判断这些BLOCK中是否存在id=3的数据。这个IO属于随机读,由LOCAL=NO前台进程来发起IO。
最后在内存中同时存在一个BLOCK,BLOCK中存在id=3这条满足条件的记录
接下来,在前台进程将id=3修改为id=5之前,需要先在log buffer中生成哪个BLOCK哪个位置从3修改为5的过程的对应记录(改变向量)
将内存buffer cache中的id=3修改为id=5,见下图中中的步骤5
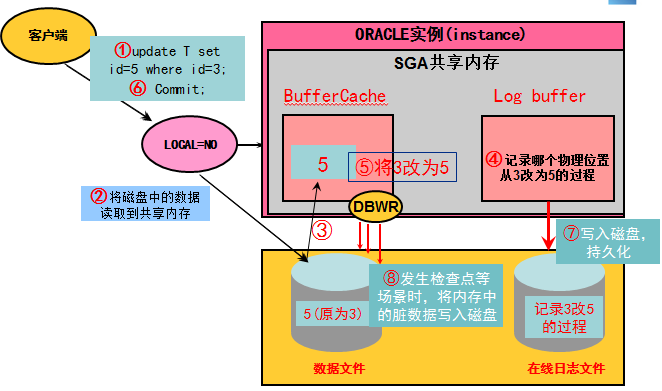
客户端发起commit
因为一旦commit,则表示数据持久化,即表示将不会随着数据库crash/os 重启而丢失,因此,此时lgwr进程需要将log buffer中id=3修改为id=5的记录写到磁盘中的在线日志文件。这个IO只能是同步IO(非异步IO),等IO确认写到磁盘后,步骤6的commit完成,返回客户端的结果为修改成功。此时虽然buffer cache内存中的数据(id=5)比磁盘中的数据文件中的数据(id=3)要新,但是因为已经确保有一份修改过程(id=3修改为id=5)写到了磁盘的在线日志文件,这个时候即可数据库掉电,也可以通过重演在线日志文件的修改记录(id=3修改为id=5),来保证数据最终被修改为5(宕机前的状态),即保证了数据不会出现丢失。
当发生checkpoint等场景时,DBWR进程将内存buffer cache中的脏数据(内存比磁盘数据要新)写到磁盘中的数据文件,这个过程是异步的。

知识点:
ORACLE为什么不把buffer cache中的脏数据也实时地在commit提交时刷到磁盘中?
Lgw进程将log buffer中的修改记录(改变向量)写到磁盘中的在线日志文件,是采用追加写到在线日志文件后面,因此LGWR的IO属于连续写。
而内存中的数据刷到磁盘中,属于随机写(每个客户端每次可能改不同物理位置的记录),随机写的性能显然不如连续写的性能好,因此ORACLE允许脏数据的存在,而不是实时地在commit提交时将脏数据刷到磁盘中,采用异步的方式往下写即可,因为lgwr的连续写已经保证了数据不会出现丢失。
压测TPS上不去--案例分享(二)
问题描述:
客户新上的一个关键业务系统,在做上线前的压力测试时,应用的并发无法达到上线前的并发指标和响应时间指标要求。压测时TPS的曲线很不稳定,如下所示: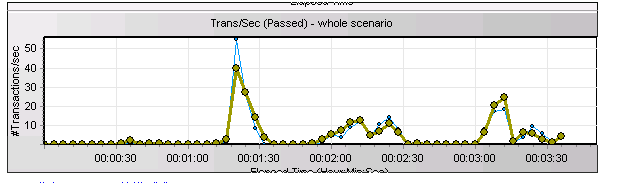
分析过程:
从上述知识点可以知道:
ORACLE中LGWR进程只有一个,由于所有进程在commit前都需要通知lgwr进程帮忙把之前在log buffer中生成的修改过程记录(改变向量)写到磁盘中。
当大量进程要同时请lgwr进程帮忙写时,就出现排队的情况。
在高并发的联机交易OLTP系统中,单进程的lgwr进程有可能成为一个大瓶颈,特别是在无法在线日志IO写性能出现问题的情况下。
因此,我们需要检查lgwr进程的状态。
通过gv$session观察RAC两个节点lgwr进程写日志的情况,结果如下图所示: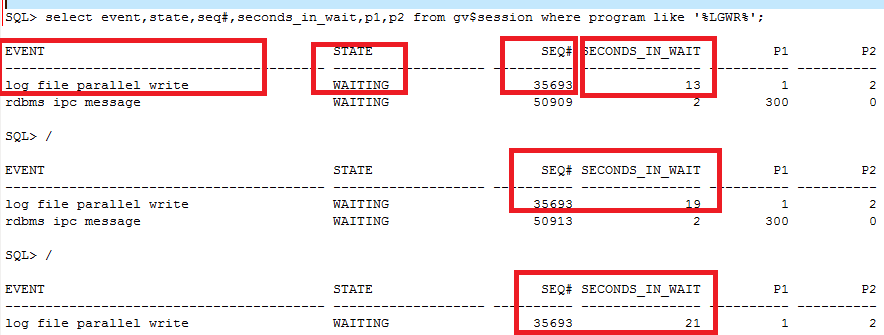


可以看到:
RAC(数据库集群)两个节点中,只有1个节点出现log file parallel write的等待,该等待表示lgwr进程正在对磁盘的在线日志文件进行写操作。
在state是waiting的情况下,节点1 log file parallel等待的seq#都是35693,但是seconds_in_wait达到了21秒。简单来说,就是lgwr进程写一个IO需要21秒!
这意味着,压测时所有并发进程必须要发生等待,等lgwr进程完成这个的IO,才可以继续通知LGWR进程帮忙刷log buffer的改变向量,因此从压测的TPS曲线来看,就是不稳定,出现了大幅衰减。
至此,我们可以肯定,IO子系统有问题
需要重点排查IO路径下的光纤线、SAN交换机、存储的报错和性能情况。
考虑到客户那边管存储的团队/部门可能不承认数据库的IO慢的证据,同时为了让对方增加排查力度,远邦让客户发出以下命令,查看多路径软件的IO情况,结果如下图所示:
节点1上出现明显的IO ERROR,并且在持续增加!
继续检查节点2,发现节点2上没有任何IO ERROR!
这个与gv$session仅有一个进程在等log file parallel write写完是完全吻合的。
原因
在铁的证据面前,客户的存储团队没有再挣扎,而是开始认认真真逐个在排查,最终在更换了光纤线后问题得到圆满解决。以下是更换光纤线后再次压测的等待事件!问题得到解决
压测的TPS曲线从原来的波浪形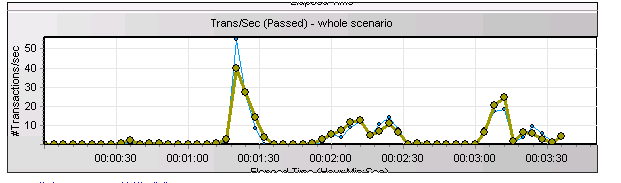
变成了如下的良好曲线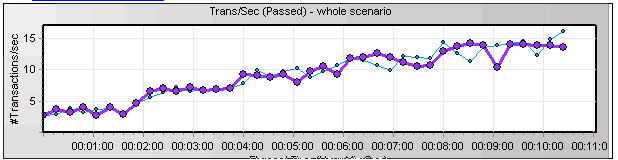


牢记于心--一幅图来总结ORACLE的IO特点
下图显示了数据库关键IO的特点
知识点
读数据由前台进程各自来完成,IO的特点是随机读,将数据读取到内存中再进行操作
DBWR进程的IO特点是随机写,DBWR进程支持多个进程同时往下刷数据,ORACLE为了避免在某一个时间点大量往下写脏块而导致磁盘压力过大,会采用异步地、慢慢地方式来刷脏块,减少IO压力,但当发出checkpoint和archive log current/all命令时,将激活大量DBWR进程全力往下刷脏块,可能对IO造成较大压力而影响整体性能,影响LGWR进程的写性能和响应时间。
Lgwr进程是连续写,有条件的情况下尽量为Redo分配单独的RAID组,物理上和其他文件分开。
并发大时性能下降严重--案例分享(三)
问题描述:
收到客户的邮件,原来客户在进行X86和小机的性能对比测试时出现以下问题:
一个高端pc server,内存32G,cpu是32核
pc server上测试8个语句并行,小机下降不明显,但在此pc server上却下降明显。
执行时间由1分多,降到7分钟。小机上始终是2分钟。
附件是AWR报告,请分析原因。
分析过程:
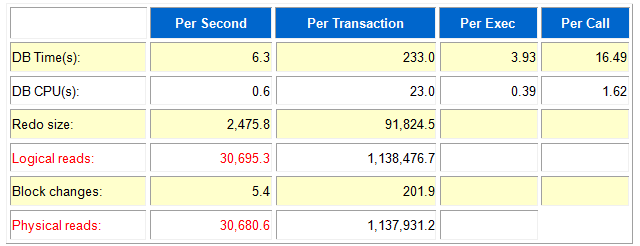 8个并行测试的情况下,逻辑读=物理读, 逻辑读表示操作内存中的BLOCK的个数,通过物理读(IO)读进内存后必然发生逻辑读。 这说明ORACLE根本没能把数据缓存到共享内存buffer cache,以便供其他进程复用。 从AWR报告中的等待事件可以看到,排在第一位的是direct path read,这是一个IO事件 即上面说的,绕开BUFFER CACHE,直接读到PGA私有内存(非共享内存)中时,单次IO的时间达到了42毫秒,太大,说明磁盘IO竞争严重,性能不佳。 但这个是原因还是结果呢?我们不妨往下看。
8个并行测试的情况下,逻辑读=物理读, 逻辑读表示操作内存中的BLOCK的个数,通过物理读(IO)读进内存后必然发生逻辑读。 这说明ORACLE根本没能把数据缓存到共享内存buffer cache,以便供其他进程复用。 从AWR报告中的等待事件可以看到,排在第一位的是direct path read,这是一个IO事件 即上面说的,绕开BUFFER CACHE,直接读到PGA私有内存(非共享内存)中时,单次IO的时间达到了42毫秒,太大,说明磁盘IO竞争严重,性能不佳。 但这个是原因还是结果呢?我们不妨往下看。 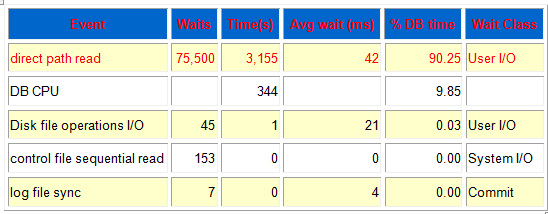 如下图所示,不再是由一个进程将数据读取到buffer cache,其他人直接复用内存中的数据,从而降低了对IO的请求次数,降低了磁盘的繁忙程度。
如下图所示,不再是由一个进程将数据读取到buffer cache,其他人直接复用内存中的数据,从而降低了对IO的请求次数,降低了磁盘的繁忙程度。 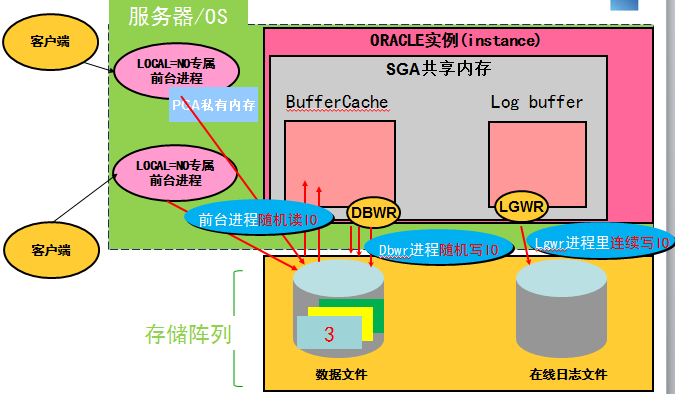 而是每个进程各自读取到自己的私有内存PGA中,每个进程执行同一条SQL都需要各自读取各自的,显然大量进程同时反复读取同一片数据,势必造成磁盘的繁忙和IO的性能下降。这就是从AWR报告中得到的分析结论。如下图所示。
而是每个进程各自读取到自己的私有内存PGA中,每个进程执行同一条SQL都需要各自读取各自的,显然大量进程同时反复读取同一片数据,势必造成磁盘的繁忙和IO的性能下降。这就是从AWR报告中得到的分析结论。如下图所示。 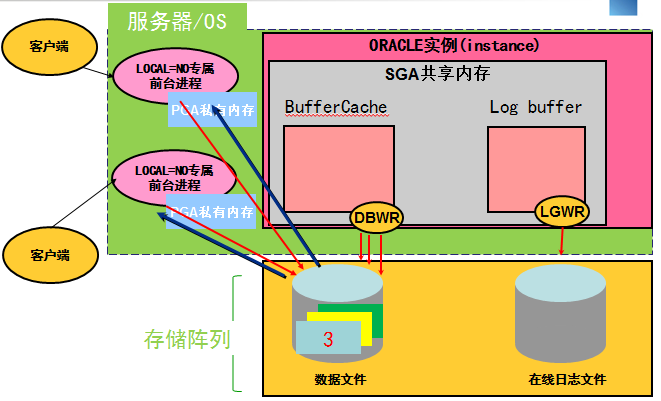




那么为什么不是一个人读取到共享内存,其他人坐享其成就好了呢?
这是11G的新特性引起的。11g下当优化器判断需要较多物理IO的时候,那么就绕开BUFFER CACHE,直接读到PGA私有内存中。
这个特性的初衷是:当ORACLE默认一次读16个BLOCK时,由于所需的部分BLOCK已经在buffer cache里了,不连续了,因此这16个BLOCK,很可能需要拆分为多次IO,导致原来的一次多块读变为了多次单块读。
但现实中,当并行个数多的时候,由于该特性,这个时候很容易把磁盘搞得很忙,IO性能下降严重,也就出现了执行时间从1分钟升至7分钟的情况。
而原来10G下的机制是:
一个会话读到内存中,其他会话坐享其成,直接读内存中的数据就可以,因此读磁盘的个数会小一些。
问题得到解决: 使用下列方法临时禁止该特性后,再次测试,问题得到解决。 alter system set event= '10949 trace name context forever, level 1' scope=spfile; --重启数据库 Shutdown immediate startup alter system register; 因此不难看出,IO慢实际上是结果,而不是原因,原因在于对同一片数据反复读取,出现太多IO了。
怎么破--什么是无效IO以及解决方法
我们不放来回顾“用一个例子说明ORACLE的工作过程和IO特点”这个章节,不难发现,其实那就是一个活生生无效IO的例子。
客户端发起update T set id=5 where id=3的SQL语句
其中,表T的大小为1G,表上不存在任何索引
在执行过程中,前台进程总计读取了磁盘中的1G的数据,经由SAN交换机传输到ORACLE共享内存中,再进行过滤,最后只有1条数据满足,最终从id=3被更新为id=5。
试想一下,如果这个表的大小不是1个G,而是100个G,也不是一个客户端发起对该表的更新,而是多个会话同时更新不同的记录,那么整个系统的IO将会异常繁忙。
我们从字典中找一个“喜”字,如果是挨页翻,挨页对,那么势必会多做很多无用功,最简单的方式就是从偏旁部首或者拼音来检索,就可以快速的找到“喜”字。
同样是找一个“喜”字,前者多翻了很多字典,即产生了很多无效IO。后者则很高效。
因此,无效IO,说到底,是SQL语句缺少一个定位数据的高效方式,导致读取了很多数据,但是不满足又被丢弃了,导致了很多无效的IO。如果,我们对表T的id字段创建索引,那么将可以快速精确定位到id=3的数据,只需要读取几个BLOCK,整体的IO量可以控制在40K以内,不是之前的1个G。
应用程序的SQL语句不够高效,是无效IO的主要原因。
SQL语句的优化不是索引那么简单,索引只是众多单表访问路径的一种,SQL优化还涉及到表连接方式优化、表连接顺序优化、SQL改写等手段,后续将会陆续介绍这些优化手段。
知识点:
我们需要有这么一个意识:
磁盘100% busy,IO响应时间很长,这很可能是因为某些不够高效的SQL语句,产生了很多无效的IO,或者导致IOPS超过了整个磁盘(阵列)所能提供的IO能力,或者是占用了无效的IO带宽导致了IO的拥堵。
磁盘繁忙,IO响应时间长,可能已经是结果,而不是导致业务慢的真正原因。
通过优化高IO的SQL,消除无效IO,将IO控制在合理范围内,提升整体IO性能。
不了解业务逻辑的情况下实现每秒IO 359M到每秒1M的优化-案例分享(四)
问题描述:
系统的IO的IO量很大,经常性地,IO的吞吐量达到每秒300M以上。
通过AWR报告,找到问题集中在一条SQL上。
问题来了,我们不是做开发的,这个业务系统的业务逻辑我们也不清楚,我们可以优化么?
答案是可以的,
实际上我们完全在可以不懂业务逻辑的情况下完成绝大部分情况的优化,我们只要获得SQL执行的过程和明细即可快速完成优化,以下这条最占IO的SQL的优化我们在1分钟内就完成了优化。
为了说明我们不需要了解业务逻辑也可以完成优化,你会发现从头到尾没有看到过任何的SQL语句 ^_^优化过程:
获取执行计划和执行明细(哪些步骤消耗多少时间,花费多少IO)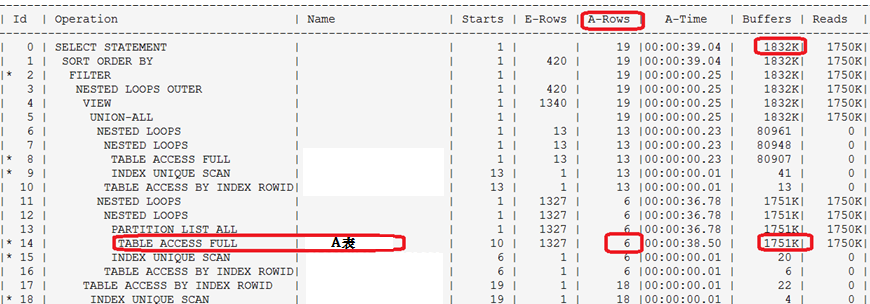

可以看到:
上述SQL的执行时间是39秒,其中id=14的步骤,占了38秒,必须优化掉该瓶颈步骤。
Id=14的步骤,reads为1750K个BLOCK,即读了1750K*8K=13G,单次执行13G,38秒读完,即每秒的IO达到359M,但是最后只返回了6条记录,该步骤对A表进行全表扫描,显然,读取13G,应用了过滤条件后,最后只返回了6条记录!很多数据在读取到内存后基本都被丢弃了。缺少定位数据的高效方式,而索引是最适合定位少量数据的。优化方式
上图id=14的谓词部分,即红色加框部分,可以看到对A表扫描了13G,主要的过滤条件是c_captialmode和c_state这两个字段把大部分数据全滤掉了,因此创建复合索引即可,命令如下
Create index idx_1 on A(c_captialmode,c_state) tablespace &tbs online;优化效果
优化后,每次执行,IO从13G下降至0 ;
优化后,执行时间从50秒下降至50毫秒
优化后,整个系统的IO从每秒359M下降到1M以下。


知识点:
在不了解业务逻辑的情况下,也可以快速实现对最消耗IO的SQL语句的快速优化。
精通数据库知识的DBA往往比不懂数据库原理的开发和程序员更懂SQL优化。
 cruboy
cruboy