

数仓概念出现于上世纪90年代, 国内最早开始的数据仓库也都在90年代末了, 刚开始大家都是按照国外大厂的指导, 照猫画虎,逐步开始建立自己的数据仓库技术体系。
这个时候大家都关注怎么建立分析模型, 怎么进行数据分析来支持决策。但是随着系统越来越庞大, 数据量越来越多, 数据处理的效率,就越来越成为大家不得不关注的热点问题了。
到底应该ETL 还是ELT,看上去只是简单地调换了一下字母的顺序,是个简单的问题,但是大多数的问题都是一学就会, 一用就废。而事实上,顺序一换,这是对数据处理流程和方法论上进一步深化的过程。
作为数据仓库从业者, 数据的抽取转换加载是永远绕不开的, 虽然现在大家一谈到数据分析, 更多的人喜欢谈数据挖掘、深度学习、数据可视化。但是随着企业数据碎片化越来越严重, 另外更多的社交数据引入到数据仓库中之后, 数据的清洗, 预处理变得更加重要。 先来看看ETL,全称为Extract - Transformation - Load,是三个单词首字母的缩写,它生动地描述了数据仓库数据预处理当中的三个关键阶段。 首先是抽取(Extract), 顾名思义,是从生产系统或者其他数据源中提取想要用到的字段, 然后用来支持后期的数据分析, 这个时候需要考虑最多的是这两个关键点: • 哪些数据需要抽取出来? • 利用什么手段来抽取? 哪些数据需要被抽取出来, 其实取决于几个因素: • 第一,哪些数据是支持目前数据模型必须用到的?了解我们的数据模型, 这个问题就很简单了。 • 第二, 这些源系统中哪些数据有分析价值?这个就有点难办了! 首先要考的是行业知识, 当然我们也有粗暴的办法, 不管三七二十一, 先把数据都拿回来, 哪怕现在先不用。将来说不定用得着, 反正数据仓库不缺空间, 再说将来再要的时候,免得改程序。 数仓概念出现于上世纪90年代, 国内最早开始的数据仓库也都在90年代末了, 刚开始大家都是按照国外大厂的指导, 照猫画虎,逐步开始建立自己的数据仓库技术体系。 这个时候大家都关注怎么建立分析模型, 怎么进行数据分析来支持决策。但是随着系统越来越庞大, 数据量越来越多,数据处理的效率,就越来越成为大家不得不关注的热点问题了。 当时有人提出一个理论,到底应该ETL 还是ELT,看上去只是简单地调换了一下字母的顺序,但是事实上,这是对数据处理流程和方法论上进一步深化的过程。 ETL 和ELT, 简单地区别就是先转换再装载, 还是先装载再转换, 前者的主要支持者自然是传统的工具厂商 Data stage 和 Informatica ,因为在这种体系架构中, 需要有一个专门的Transformation Server, 数据的复杂处理和映射,主要在转换服务器上进行处理。 而ELT的主要支持者就是数据库厂商, 因为它们希望所有的数据处理工作都在数据库内部完成, 最大化地发挥数据库海量数据并行处理的能力。 两种方式各有优劣, ETL 重转换, 可以在转换服务器上直接进行复杂的处理, 但是受制于转换服务器的处理和吞吐能力, 海量数据的处理效率堪忧。 但是ELT的缺点在于:如果大量的数据转换都由存储过程实现的话, 那么整个数据处理过程中的元数据管理就变得非常困难。随着数据仓库的技术发展, 最终ELT 还是略占上风, 因为, 如果把数据仓库各层之间的汇总也看作是Transformation的话, 那自然是Load 在先, Transformation在后。 ELT大行其道的同时, 也给数据仓库的技术带来了几个问题, 下面我跟你简单说说。 第一个问题,就是大量的存储过程怎么调度的问题。 我见到过一家国内大型科技企业的数据仓库, 有超过一万个数据处理脚本。随着业务发展, 这些脚本的数量还是继续增加。 那么如此多的脚本,我们不得不去思考这样的几个问题: • 怎么进行调度? • 怎么实现断点续跑? • 怎么进行小范围回退后重新启动而不需要所有一万多脚本重新跑? • 一旦中间数据处理异常之后,如何清理错误的脏数据? 这么多的脚本进行调度,还有先后依赖关系,怎么确定ETL 脚本的分层管理, 如何实现整个调度过程的图形化展现和监控,就变成了一个新的问题。 第二个问题, 元数据管理的问题。我记得我最初写ETL 脚本的时候, 只考虑了数据怎么从源取出来, 然后再怎么经过mapping ,生成最终结果, 中间的过程完全不需要对外输出过程信息。 但是这样一来, 我们就很容易陷入另外一种僵局, 就如同前面提到的那家企业, 一万多脚本, 鼎盛时期有400多开发人员在做开发, 但是一旦人员流失, 换新人怎么维护这个代码?难度自然就直线上升了。 同时, 如果在结果展示的时候 想知道某个数据,是经过什么口径统计过来的?那就完全不知道了, 因为整个脚本就是个黑盒子, 大家都不知道数据之间的继承沿革关系。所以怎么利用存储过程,自动生成ETL 元数据, 就是第二个问题。 第三个问题, 存储过程效率问题。所有数据转换都利用数据库的特性, 那么这个时候的数据处理效率就会全面依赖数据库的特性,这种处理难以避免的就是多个大表Join, 排序。那么您选择的数据库在大表连接的时候怎样效率最高,怎么利用数据库提供的函数或者特性,加速数据处理效率,就变成了程序员必须要了解的一个知识点。 曾经碰到一个项目, 程序员对数据库特征不太了解, 同时为了程序易读, 就通过临时表来简化过程, 看上去是个很好的习惯。 但是极端情况下, 原来只需要一个复杂SQL 就能解决的问题, 数据反复写临时表20多次,系统上线之后,还在纳闷, 数据逻辑完全没变, 怎么就跑不动了呢? ETL 还是ELT , 看上去是个简单的问题, 但是大多数的问题都是一学就会, 一用就废。就像在驾校学了怎么起步?怎么停车, 怎么换挡, 但是真正上路才发现还是会各种手忙脚乱。 就今天探讨的问题,关键还是需要在设计ETL 和交付ETL 项目的时候, 要有大局观。多想想执行效率, 维护难度,多多输出元数据, 这样一来,我相信你就已经踏上了正确道路, 迈开了第一步。 关于作者:祁国辉,网名"atiger",前 Oracle 云平台事业部电信行业技术总监。拥有超过25年数据库和数据仓库HK经验。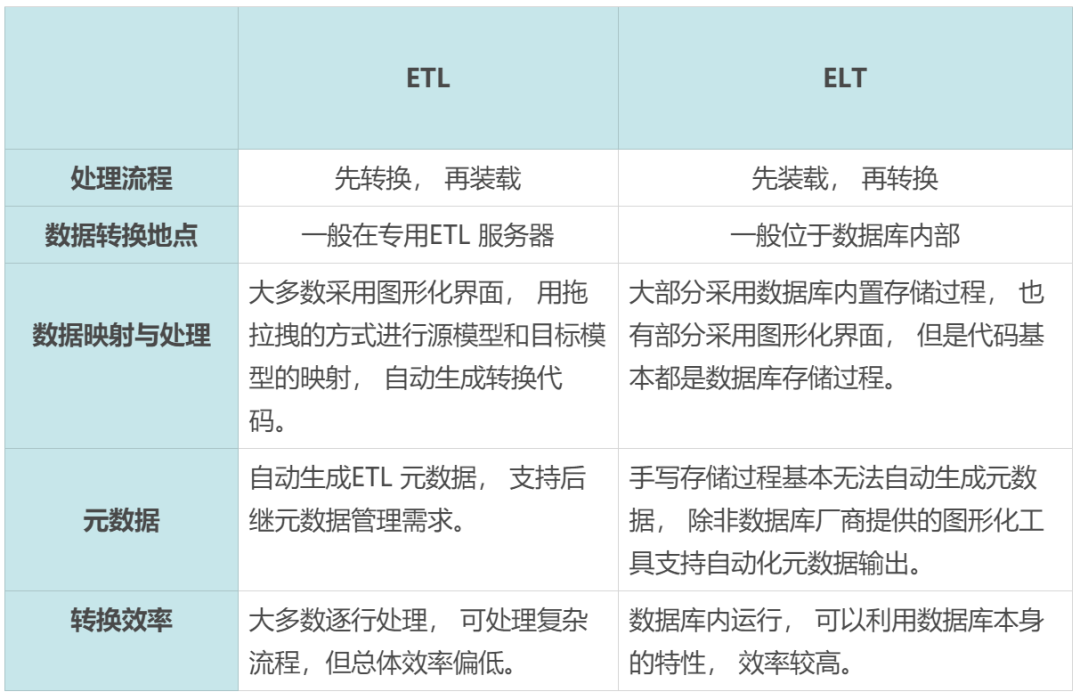

 cruboy
cruboy