

Flink和ClickHouse分别是实时计算和(近实时)OLAP领域的翘楚,也是近些年非常火爆的开源框架,很多大厂都在将两者结合使用来构建各种用途的实时平台,效果很好。关于两者的优点就不再赘述,本文来简单介绍笔者团队在点击流实时数仓方面的一点实践经验。
点击流及其维度建模
所谓点击流(click stream),就是指用户访问网站、App等Web前端时在后端留下的轨迹数据,也是流量分析(traffic analysis)和用户行为分析(user behavior analysis)的基础。点击流数据一般以访问日志和埋点日志的形式存储,其特点是量大、维度丰富。以我们一个中等体量的普通电商平台为例,每天产生200+GB、十亿条左右的原始日志,埋点事件100+个,涉及50+个维度。
按照Kimball的维度建模理论,点击流数仓遵循典型的星形模型,简图如下。
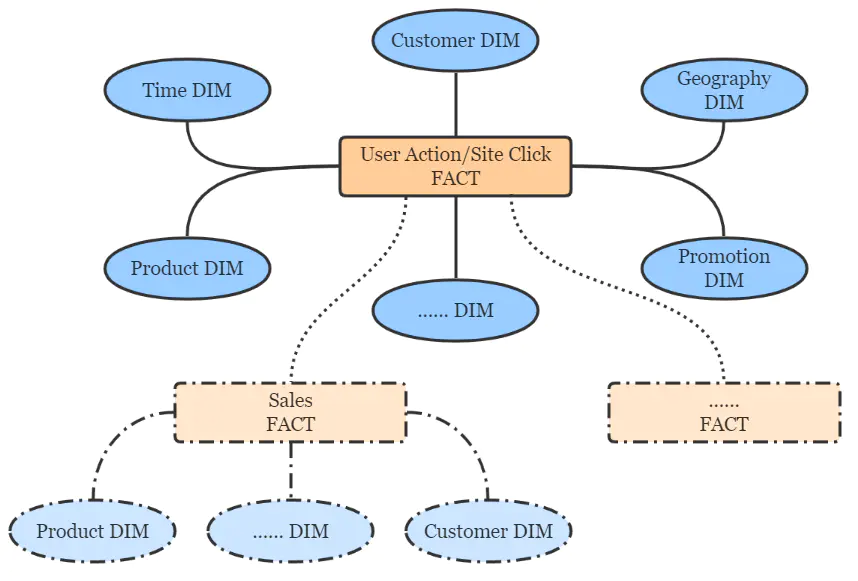
点击流数仓分层设计
点击流实时数仓的分层设计仍然可以借鉴传统数仓的方案,以扁平为上策,尽量减少数据传输中途的延迟。简图如下。
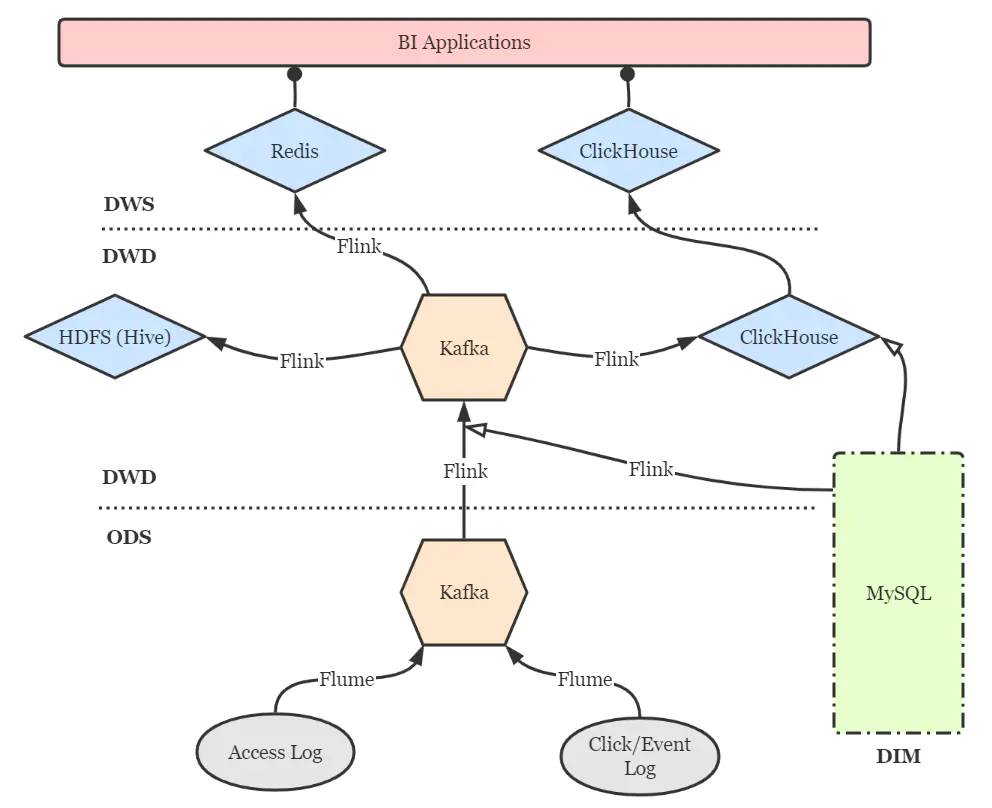
DIM层:维度层,MySQL镜像库,存储所有维度数据。 ODS层:贴源层,原始数据由Flume直接进入Kafka的对应topic。 DWD层:明细层,通过Flink将Kafka中数据进行必要的ETL与实时维度join操作,形成规范的明细数据,并写回Kafka以便下游与其他业务使用。再通过Flink将明细数据分别写入ClickHouse和Hive打成大宽表,前者作为查询与分析的核心,后者作为备份和数据质量保证(对数、补数等)。 DWS层:服务层,部分指标通过Flink实时汇总至Redis,供大屏类业务使用。更多的指标则通过ClickHouse物化视图等机制周期性汇总,形成报表与页面热力图。特别地,部分明细数据也在此层开放,方便高级BI人员进行漏斗、留存、用户路径等灵活的ad-hoc查询,这些也是ClickHouse远超过其他OLAP引擎的强大之处。
要点与注意事项
Flink实时维度关联
Flink框架的异步I/O机制为用户在流式作业中访问外部存储提供了很大的便利。针对我们的情况,有以下三点需要注意:
使用异步MySQL客户端,如Vert.x MySQL Client。AsyncFunction内添加内存缓存(如Guava Cache、Caffeine等),并设定合理的缓存驱逐机制,避免频繁请求MySQL库。实时维度关联仅适用于缓慢变化维度,如地理位置信息、商品及分类信息等。快速变化维度(如用户信息)则不太适合打进宽表,我们采用MySQL表引擎将快变维度表直接映射到ClickHouse中,而ClickHouse支持异构查询,也能够支撑规模较小的维表join场景。未来则考虑使用MaterializedMySQL引擎(当前仍未正式发布)将部分维度表通过binlog镜像到ClickHouse。
Flink-ClickHouse Sink设计
可以通过JDBC(flink-connector-jdbc)方式来直接写入ClickHouse,但灵活性欠佳。好在clickhouse-jdbc项目提供了适配ClickHouse集群的BalancedClickhouseDataSource组件,我们基于它设计了Flink-ClickHouse Sink,要点有三:
写入本地表,而非分布式表,老生常谈了。 按数据批次大小以及批次间隔两个条件控制写入频率,在part merge压力和数据实时性两方面取得平衡。目前我们采用10000条的批次大小与15秒的间隔,只要满足其一则触发写入。 BalancedClickhouseDataSource通过随机路由保证了各ClickHouse实例的负载均衡,但是只是通过周期性ping来探活,并屏蔽掉当前不能访问的实例,而没有故障转移——亦即一旦试图写入已经失败的节点,就会丢失数据。为此我们设计了重试机制,重试次数和间隔均可配置,如果当重试机会耗尽后仍然无法成功写入,就将该批次数据转存至配置好的路径下,并报警要求及时检查与回填。
当前我们仅实现了DataStream API风格的Flink-ClickHouse Sink,随着Flink作业SQL化的大潮,在未来还计划实现SQL风格的ClickHouse Sink,打磨健壮后会适时回馈给社区。另外,除了随机路由,我们也计划加入轮询和sharding key hash等更灵活的路由方式。
还有一点就是,ClickHouse并不支持事务,所以也不必费心考虑2PC Sink等保证exactly once语义的操作。如果Flink到ClickHouse的链路出现问题导致作业重启,作业会直接从最新的位点(即Kafka的latest offset)开始消费,丢失的数据再经由Hive进行回填即可。
ClickHouse数据重平衡
ClickHouse集群扩容之后,数据的重平衡(reshard)是一件麻烦事,因为不存在类似HDFS Balancer这种开箱即用的工具。一种比较简单粗暴的思路是修改ClickHouse配置文件中的shard weight,使新加入的shard多写入数据,直到所有节点近似平衡之后再调整回来。但是这会造成明显的热点问题,并且仅对直接写入分布式表才有效,并不可取。
因此,我们采用了一种比较曲折的方法:将原表重命名,在所有节点上建立与原表schema相同的新表,将实时数据写入新表,同时用clickhouse-copier工具将历史数据整体迁移到新表上来,再删除原表。当然在迁移期间,被重平衡的表是无法提供服务的,仍然不那么优雅。
 cruboy
cruboy