NLP的技术原理
首先,我们要弄明白,NLP任务(自然语言处理,AI的一个技术领域,即文本类的AI任务)的核心逻辑是一个“猜概率”的游戏。
比如说,“我今天被我朋友___”,经过大量的数据训练后,AI预测空格出会出现的最高概率的词是“放鸽子了”,那么CPU就会被填到这个空格中,从而答案产生——“我今天被我朋友放鸽子了”
虽然非常不可思议,但事实就是这样,现阶段所有的NLP任务,都不意味着机器真正理解这个世界,他只是在玩文字游戏,进行一次又一次的概率解谜,本质上和我们玩报纸上的填字游戏是一个逻辑。只是我们靠知识和智慧,AI靠概率计算。
在近几年的自然语言处理领域中,BERT和GPT是两个引起广泛关注的语言模型。特别是在GPT3.5的基础上进行微调的chatGPT,持续出圈和火爆。chatGPT的火爆表明了预训练语言模型在自然语言处理领域具有巨大的潜力,并且在提高自然语言理解和生成能力方面取得了显著的进展。这可能会带来更多的应用和更广泛的接受。
BERT和GPT也都是基于预训练语言模型的思想,通过大量的语料训练而得到的高效率的语言模型。为了帮助大家更好的理解和选择不同的技术和模型,本文将着重比较BERT和GPT这两个语言模型之间的区别,为大家提供一个全面的认识。
Transformer
大约在6年前,一篇大名鼎鼎的论文《Attention Is All You Needed》正式发表,它第一次提出了注意力机制(Attention),并且在Attention的基础上创造了一个全新的NLP(自然语言处理)模型Transformer。
Transformer是GPT和BERT的前身。谷歌和OpenAI在自然语言处理技术上的优化,都是基于这个模型。
更多关于的Transformer可以看文章:ChatGPT与Transformer(无公式版)
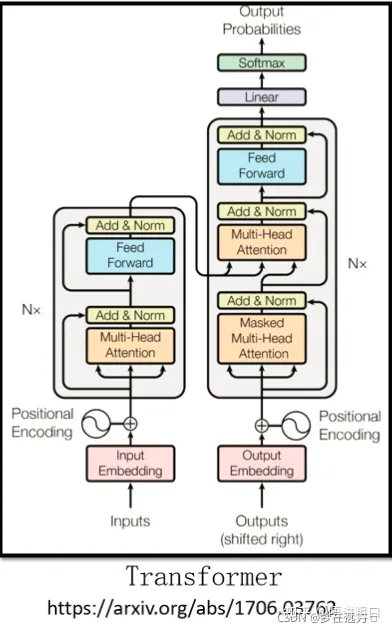
而在目前的“猜概率”游戏环境下,基于大型语言模型(LLM,Large Language Model)演进出了最主流的两个方向,即Bert和GPT。
其中BERT是之前最流行的方向,几乎统治了所有NLP领域,并在自然语言理解类任务中发挥出色(例如文本分类,情感倾向判断等)。
而GPT方向则较为薄弱,最知名的玩家就是OpenAI了,事实上在GPT3.0发布前,GPT方向一直是弱于BERT的(GPT3.0是ChatGPT背后模型GPT3.5的前身)。
上图是Transformer的一个网络结构图,Bert的网络结构类似于Transformer的Encoder部分,而GPT类似于Transformer的Decoder部分。单从网络的组成部分的结构上来看,其最明显的在结构上的差异为Multi-Head-Attention和Masked Multi-Head-Attention。
不论是早期的利用LDA、RNN等统计模型或很小的深度学习模型的时代,还是后来利用BERT等预训练配合微调的时代,技术所提供的能力是相对原子化的,距离实际的应用场景有一定的距离。就拿前面举的让ChatGPT根据要求写英文邮件的例子,按照此前的做法,可能需要先抽取实体、事件等内容(比如时间、地点、事件等),然后通过模版或是模型形成邮件的样式,再通过一个翻译模型转化为英文。当然如果数据量足够训练端到端模型的情况下,也可以跳过中间的若干步骤。但不论采用哪种方式,要么需要将最终的场景拆解成原子化的NLP任务,要么需要对应的标注数据。而对于ChatGPT来说,只需要一个合适的指令。
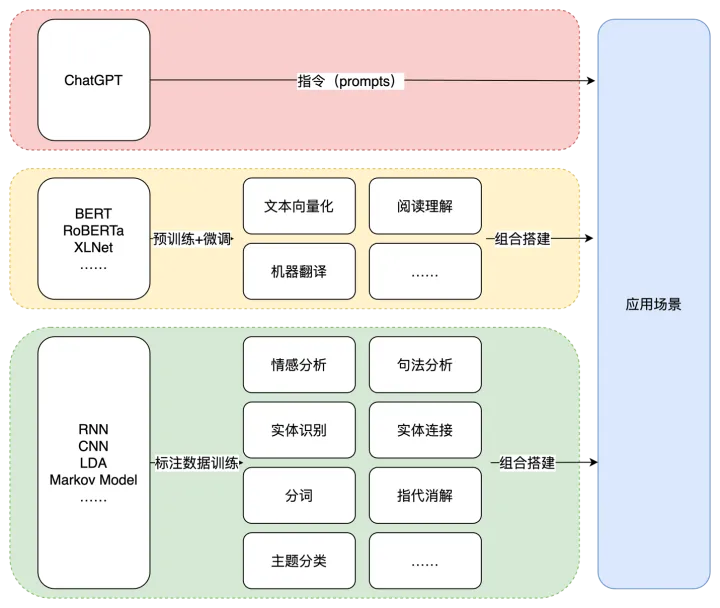
BERT和GPT两者之间的差别。
BERT:双向 预训练语言模型+fine-tuning(微调)
GPT:自回归 预训练语言模型+Prompting(指示/提示)
BERT和GPT是近年来自然语言处理领域中非常重要的模型,它们代表了现代NLP技术的发展。需要注意的是, 这两个模型并不是NLP领域唯一的重要模型,在近几年中还有很多其他的模型和方法被提出,也在被广泛使用。
BERT
BERT,全称为Bidirectional Encoder Representations from Transformers,是由Google AI Language团队在2018年提出的预训练语言模型。BERT是基于Transformer网络架构和预训练语言模型的思想而提出的。它可以在不同语言任务上达到最先进的水平。
BERT展示了预训练语言模型对于自然语言理解任务的巨大潜力,在诸多任务中取得了突破性进展,成为了自然语言理解任务中的基准模型。
BERT的训练过程分为预训练和微调两部分。
预训练是BERT模型的基础部分,它包括使用大量的文本来训练语言模型。在预训练阶段,BERT模型会学习到大量的语言知识,如词汇、语法、句子结构等。预训练的目的是为了让BERT模型具有足够的语言能力来处理各种不同的自然语言任务。
微调过程是在预训练模型的基础上,使用更小的标记数据来调整模型参数。这样可以使得模型更适合特定的任务。大部分使用BERT技术来装备NLP能力的企业,只需要通过微调来让模型更适合特定的任务,而不需要重新预训练。 而预训练过程需要大量的计算资源和时间,所以微调是一种更加高效和经济的方式。
BERT主要用于自然语言理解,具体应用如下:
问答系统:BERT可以在问答系统中用来理解问题并生成答案。
句子相似度比较:BERT可以用来比较两个句子之间的相似程度。
文本分类:BERT可以用来对文本进行分类。
情感分析:BERT可以用来对文本进行情感分析。
命名实体识别:BERT可以用来识别文本中的命名实体。
GPT
GPT(Generative Pre-trained Transformer)则是由OpenAI研究团队在2018年提出的一种语言模型。其起源于对传统预训练语言模型(如ELMO和ULMFit)的改进和升级,采用了Transformer架构,并通过预训练+微调的方式实现语言理解和生成。
GPT则展示了预训练语言模型在语言生成任务中的潜力。它被广泛应用于各种文本生成任务,如文本自动完成、对话生成、文章摘要等。
GPT预训练的数据来源是网络上的大量文本数据,例如维基百科,新闻文章等。模型首先学习了基本的语言知识和结构,然后再在特定的任务上进行微调。微调过程中,模型会根据特定任务的需要来学习相关的知识。
GPT能够完成各种自然语言处理任务,在文本生成方面表现尤为优秀,可以生成各种类型的文本,如文章、诗歌、对话等。其主要具体应用如下:
文本生成:GPT可以用来生成文本。
文本自动完成:GPT可以用来自动完成用户输入的文本。
语言翻译:GPT可以用来生成翻译后的文本。
对话生成: GPT可以用来生成对话
摘要生成: GPT可以用来生成文章摘要
Bert与GPT预训练任务区别
在Bert与GPT的预训练任务的选取上,Bert与GPT所用的模型也存在着较大的差异。
Bert——Masking Input
在Bert的预训练任务中,Bert主要使用“填空题"的方式来完成预训练:
随机盖住一些输入的文字,被mask的部分是随机决定的,当我们输入一个句子时,其中的一些词会被随机mask。
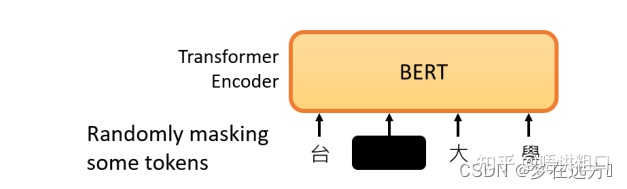
mask的具体实现有两种方法。
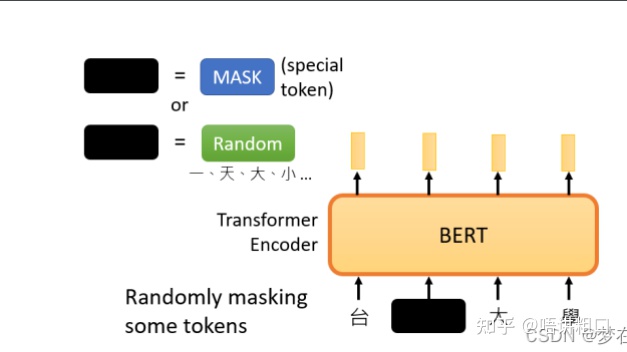
第一种方法是,用一个特殊的符号替换句子中的一个词,我们用 "MASK "标记来表示这个特殊符号,可以把它看作一个新字,这个字完全是一个新词,它不在字典里,这意味着mask了原文。
另外一种方法,随机把某一个字换成另一个字。中文的 "湾"字被放在这里,然后可以选择另一个中文字来替换它,它可以变成 "一 "字,变成 "天 "字,变成 "大 "字,或者变成 "小 "字,我们只是用随机选择的某个字来替换它
两种方法都可以使用。使用哪种方法也是随机决定的。因此,当BERT进行训练时,向BERT输入一个句子,先随机决定哪一部分的汉字将被mask。
mask后,一样是输入一个序列,我们把BERT的相应输出看作是另一个序列,接下来,我们在输入序列中寻找mask部分的相应输出,然后,这个向量将通过一个Linear transform,输入向量将与一个矩阵相乘,然后做softmax,输出一个分布。。
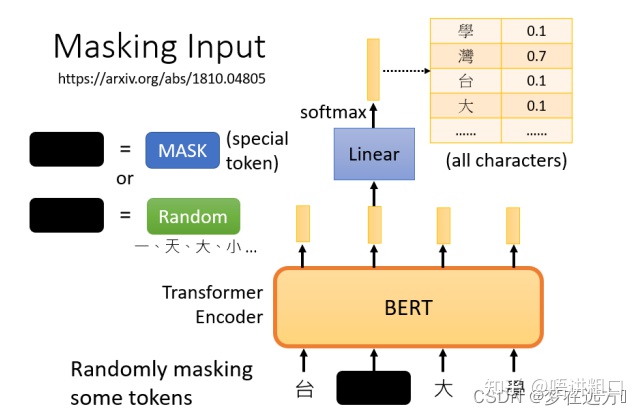
这与我们在Seq2Seq模型中提到的使用transformer进行翻译时的输出分布相同。输出是一个很长的向量,包含我们想要处理的每个汉字,每一个字都对应到一个分数。
在训练过程中。我们知道被mask的字符是什么,而BERT不知道,我们可以用一个one-hot vector来表示这个字符,并使输出和one-hot vector之间的交叉熵损失最小。
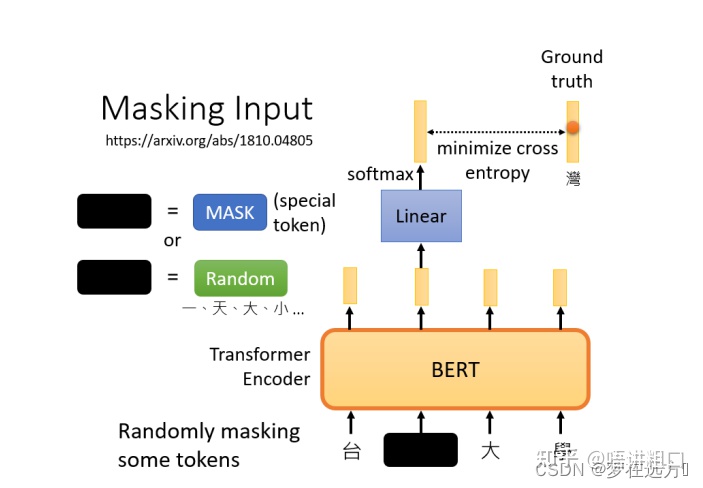
BERT要做的是,预测什么被盖住。被掩盖的字符,属于 "湾"类。
在训练中,我们在BERT之后添加一个线性模型,并将它们一起训练,尝试去预测被覆盖的字符是什么。
GPT——Predict Next Token
GPT要做的任务是,预测接下来,会出现的token是什么
举例来说,假设训练资料里面,有一个句子是台湾大学,那GPT拿到这一笔训练资料的时候,选取BOS这个Token所对应的输出,作为Embedding的结果,用这个embedding去预测下一个应该出现的token是什么
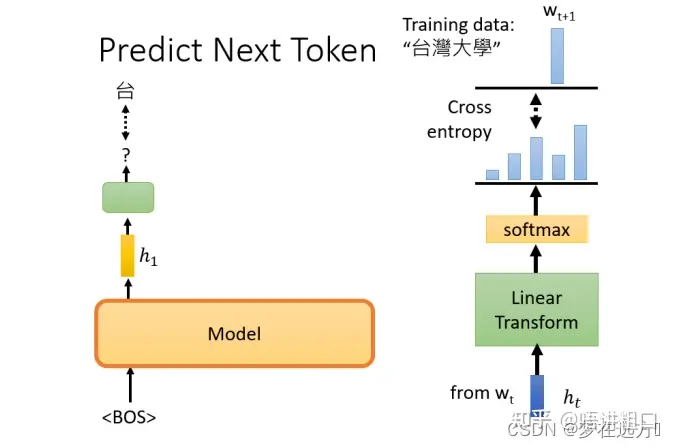
那在这个句子里面,根据这笔训练资料,下一个应该出现的token是"台",要训练模型,根据第一个token,根据BOS给的embedding,那它要输出"台"这个token
这个部分,有一个embedding,这边用h来表示,然后通过一个Linear Transform,再通过一个softmax,得到一个概率分布,我们希望这个输出的概率分布,跟正确答案的交叉熵越小越好。
接下来要做的事情,就是以此类推了,输入BOS跟"台",它产生embedding,接下来它会预测,下一个出现的token是什么,以此类推来训练模型。

相同数据集体量的话,bert或许更好。但如果预训练数据暴涨的话,两者的差别就出来了。
gpt网络的训练是不需要标注数据的,这是它天然非常非常合适于超大数据量的情况的特点。
Bert和GPT使用方法的区别
对于Bert和GPT,其本意是提供一个预训练模型,使得人们可以方便的将其运用于下流(downstream)任务当中去。当然,这两种模型最后使用的方法也是有一些区别的。
Bert的使用方法——以情感分类为例
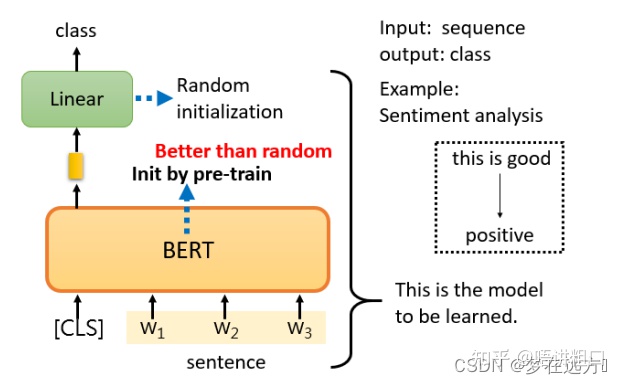
只要给它一个句子,也就是你想用它来判断情绪的句子,然后把CLS标记放在这个句子的前面,扔到BERT中,这4个输入实际上对应着4个输出。然后,我们只看CLS的部分。CLS在这里输出一个向量,我们对它进行Linear transform,也就是将它乘以一个Linear transform的矩阵,然后进行Softmax,就可以得到情感分类的结果。
Bert的使用大多如此,用CLS对应的Output作为Embedding的结果,然后根据不同的任务进行对应的操作来fine-turing,从某方面而言,更像是利用深度学习对文本进行特征表示的过程。
GPT的使用方法
对于GPT使用,由于GPT的参数是Bert的4倍有余,使得去fine-turing一个模型需要更长,更大的训练时间。因此GPT提出了一个更加“疯狂”的使用方式,一种更接近于人类的使用方式。
没有进行梯度下降的"Few short leaning",也就GPT论文所提到的“In-context learning”
举例来说假设要GPT这个模型做翻译

先打Translate English to French,这个句子代表问题的描述
然后给它几个范例
最后接下来给一个Cheese的词,让他翻译成法语。
fine-tuning VS Prompting
假设现在预训练好的大模型要针对具体领域工作了,他被安排成为一名鉴黄师,要分辨文章到底有没有在搞黄色。那么BERT和GPT的区别在哪里呢?
BERT:fine-tuning(微调)。微调是指模型要做某个专业领域任务时,需要收集相关的专业领域数据,做模型的小幅调整,更新相关参数。
例如,我收集一大堆标注数据,然后喂给模型进行训练,调整他的参数。经过一段时间的针对性学习后,模型对于分辨你们是否搞黄色的能力更出色了。这就是fine-tuning,二次学习微调。
GPT:Prompting。prompt是指当模型要做某个专业领域的任务时,我提供给他一些示例、或者引导。但不用更新模型参数,AI只是看看。
例如,我提供给AI模型10张黄色图片,告诉他这些是搞黄色的。模型看一下,效果就提升了。大家可能会说,这不就是fine-tuning吗?不是一样要额外给一些标注数据吗?
两者最大的区别就是:这种模式下,模型的参数不会做任何变化升级,这些数据就好像仅仅是给AI看了一眼——嘿,兄弟,参考下这个,但是别往心里去。
不可思议吧,但他成功了!而更令人疯狂的是,到目前为止,关于prompt明明没有对参数产生任何影响,但确实又明显提升了任务的效果,还是一个未解之谜。暂时而言大家就像程序员对待bug一样——I don't know why , but it work lol .
这种Prompt其实就是ICT(in-Context Learning),或者你也可以称为Few shot Promot,用大白话说就是“给你一点小提示”。
同时还有另外一种Promot,称之为Zero shot Promot。ChatGPT就是Zero shot promot模式,目前一般称之为instruct了。
这种模式下用户直接用人类的语言下达命令,例如“给我写首诗”,“给我做个请教条”,但是你可以在命令的过程中用一些人类语言增强AI的效果,例如“在输出答案之前,你先每一步都想一想”。就只是增加这样一句话,AI的答案效果就会明显提升。
“One-shot” Learning “Zero-shot” Learning
例如我们在考听力测验的时候,都只给一个例子而已,那GPT可不可以只看一个例子,就知道它要做翻译,这个叫One-shot Learning
还有更厉害的是Zero-shot Learning,直接给它一个叙述,说现在要做翻译了,来看GPT能不能够自己就看得懂,就自动知道说要来做翻译这件事情。

GPT在没有微调的情况下,这种使用方法虽然准确率不够高,但是随着GPT参数量的增加,在一定程度上仍然有着一定的准确率。
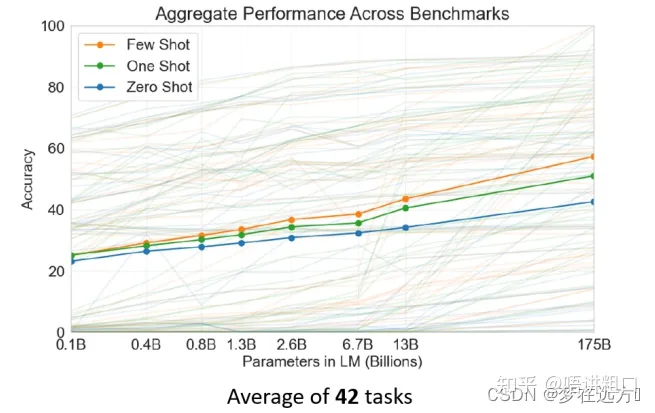
这就是GPT相比较于Bert更加独特的一种使用方式。
BERT和GPT的主要区别总结
从上面的介绍看,BERT和GPT都是基于Transformer的预训练模型,都包含了预训练和微调的过程。都能够应用于各种NLP的任务。但实际上,他们又有许多不同之处,在我们选择时,需要稍加注意。
GPT的训练相对于BERT有以下不同之处:
GPT使用的是Transformer模型,而BERT使用的是双向Transformer模型。
GPT的预训练数据来源是大量的网络文本数据,而BERT的预训练数据来源是两个大型语料库,包括Wikipedia和BooksCorpus。
GPT预训练过程中,采用了语言模型的方法,即通过预测下一个词来学习语言模型,而BERT预训练过程中采用了双向预测的方法,即通过预测句子中丢失的词来学习语言模型。
GPT微调时,需要指定输入输出的语言模型任务,而BERT微调时,可以应用在多种任务上,例如文本分类、命名实体识别等。
GPT和BERT在使用场景上有明显的不同:
GPT主要用于自然语言生成任务,如文本自动补全、问答系统、文本翻译等。它可以根据给定的文本上下文生成有意义的文本,并且能够产生连贯的、人类水平的文本。
BERT则主要用于自然语言理解任务,如问题回答、文本分类、句子关系分析等。它可以理解文本中的语义和关系,并能够找出语句之间的联系。
GPT在文本生成场景中更常见,如聊天机器人,智能问答系统等。BERT在文本理解场景中更常见,如文本分类,问题回答等。
GPT对于文本生成更为敏感,而BERT对于文本理解更为敏感。
GPT在进行文本生成时需要较长的上下文,而BERT在进行文本理解时需要较短的上下文。
总的来说,GPT主要用于文本生成任务,而BERT则主要用于文本理解任务。
总结
BERT模型虽然也是采用和GPT一样的Transformer模型结构,但它几乎就是为「无监督预训练+下游任务微调」的范式量身定制的模型。和GPT相比,BERT所使用的掩码语言模型任务(Masked Language Model)虽然让它失去了直接生成文本的能力,但换来的是双向编码的能力,这让模型拥有了更强的文本编码性能,直接的体现则是下游任务效果的大幅提升。而GPT为了保留生成文本的能力,只能采用单向编码。以当年的眼光来看,BERT绝对是一个更加优秀的模型。因为既然BERT和GPT两者都是采用「预训练+微调」的范式,并且下游任务依然是分类、匹配、序列标注等等「经典」的NLP任务形式,那么像BERT模型这种更注重特征编码的质量,下游任务选一个合适的损失函数去配合任务做微调,显然比GPT这种以文本生成的方式去「迂回地」完成这些任务更加直接。从BERT模型出来以后,「无监督训练+下游任务微调」的范式便奠定了它的霸主地位,各类沿着BERT的思路,琢磨「如何获得更好的文本特征编码」的方法大量涌现,以至于GPT这个以生成式任务为目标的模型显得像一个「异类」。马后炮地说,如果当时OpenAI「顺应大势」,放弃生成式预训练这条路,也许我们要等更长的时间才能见到ChatGPT这样的模型。
总的来说,BERT和GPT都是非常强大的语言模型,它们都是近年来NLP领域的重要突破。BERT是基于转移学习的思想开发的,主要用于解决语言理解相关的任务,如问答、语义关系抽取等。而GPT则是基于生成式预训练的思想开发的,主要用于解决语言生成相关的任务,如文本生成、机器翻译等。在使用场景上,BERT更适用于在已有标注数据上微调的场景,而GPT更适用于在大量未标注数据上预训练的场景。总之,BERT和GPT都是非常优秀的语言模型,在不同的任务和场景中都有很好的表现。
参考资料:
Bert与GPT的区别_梦在远方☯的博客-CSDN博客_bert gpt
 cruboy
cruboy